Constraining Types with Regular Expressions
Structures with Constraints
Here's a picture of an element of a binary tree type:

The leaves correspond to elements and the letters indicate the type of those elements. If we read the leaves from left to right they match the regular expression A*B*. We can define a binary type whose leaves always match this string by making use of dissections. Similarly we can construct all kinds of other structures, such as lists and more general trees, whose leaves match this expression.
But can we make structures that match other regular expressions? Here are some examples:
1. Structures that match the expression An for some fixed n. These are structures, like trees, that have a fixed size. For the case n=5 we need a type that includes elements like:

2. Structures that match (AA)*. These are structures like trees with an even number of elements. This is easy for lists. We can just use a list of pairs. But it's more complex for trees because subtrees may have odd or even size even though the overall structure is even in size. We could also generalise to ((AA)n)* for some fixed n.
3. Structures that match A*1A*. Here's an example:
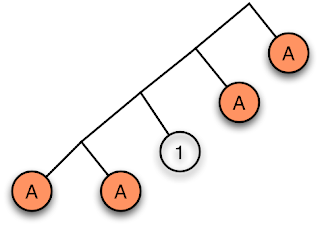
The element marked 1 is of unit type (). It's a 'hole'. So this regular expression is a derivative type. We can also construct a variety of types like those matching A*BA*CB* by using a mixture of dissection and differentiation:

4. A bytestring- or rope-like type used to represent a string that is statically guaranteed to match a given regular expression.
5. Many kinds of other constraints you could imagine on a datastructure. Like trees which are guaranteed not to have two neighbouring leaves of the same type, or whose sequence of leaves never contain a certain subsequence.
So the challenge is this: can we implement a uniform way of building any container type to match any regular expression we want?
We'll need some extensions:
Let l(x) be the type of lists of elements of type x. We can define a list type through
Algebraically we can write this as

Note that I have overloaded the numeral '1' to mean both the type with one element (when labelling an edge) and to mean the state numbered 1 (when labelling a vertex).
Define the Lij(x) to be the type of lists whose sequence of elements correspond to all possible paths from state i to state j. A list in Lij(x) is either an empty list, or constructed from a first element and a list. If we combine an element and a list, the combination has to match a possible path from i to j. There are a number of ways we could do this. The element could correspond to a transition from i to k. But if this is the case, then the remainder of the list must correspond to a path from k to j. So we must replace Cons with something that for its first argument takes a type corresponding to a single automaton step from i to k. For its second argument it must take an element of Lkj(x). The set of paths from i to j that correspond to a single step is the (i,j)-th element of the transition matrix for the automaton. This is Xij(x) where
On the other hand, we also need to replace Nil with a version that respects transitions too. As Nil takes no arguments, it must correspond to paths of length zero in the automaton. The only such paths are zero length paths from a state to itself. So the matrix for such paths is:
Let's also define the matrix L(x)= (Lij(x)).
The words above boil down to:
We can rewrite this using standard matrix notation:
We started this section by considering the specific case of the pattern x*1x* with a corresponding matrix X(x). Because X10=0 and X00=X11 it's not hard to see that any type T we constrain using this regular expression will also have similar 'shape', ie. T10=0 and T00=T11. So we can write
where by definition, t(x)=T00(x) and t'(x)=T01(x). Suppose we have two such collections of types, (Sij) and (Tij). Now consider the types of pairs where the first element is of type Sij and the second of Tjk. Then the leaves of the pair structure correspond to a path from i to k. So we have
Multiply out and we find that
Although I talked specifically about differentiation, much of what I said above applies for any finite state automaton whose edges are labelled by types. The best thing now is probably to put together some code to see how this all looks.
A Specification
If you haven't checked Brent Yorgey's solution to my problem last week, now is a good opportunity. My code is a generalisation of that but it may be helpful to look at Brent's specialisation first.
The goal is to be able to define a transition matrix like this. ('K' is an abbreviation for 'constant' matrix.)
We'd like then to able to form the matrix of fixed points of Y = ListF X Y. In this case, ordinary lists should appear as the element at position (0,0) in the matrix:
Derivatives of lists should appear at (0,1) so we want
The Implementation
We'll need a type with no elements:
We can now define matrix addition through pointwise addition of the elements:
Now we need some types to represent our functors:
To turn these into usable types we need to implement the homomorphism I described above. So here are the rules laid out formally:
We can explicitly implement the isomorphism with the more familiar list type:
What have we learnt?
We haven't just solved the original problem. We've shown that derivatives and dissections are special cases of a more general operation. Take a look at the definition of D x again. we can think of it as xI+Delta where Delta is the matrix
We can now go back and look at the matrix form of divided differences on wikipedia. I hope you can now see that the matrix Tid(x0,...,xn-1) defined there is nothing other than a transition matrix for this automaton:

In fact, we can use what we've learnt about regular expressions here to solve some numerical problems. But I won't write about that until the next article.
By the way, I think what I've described here can be viewed as an application of what Backhouse talks about in these slides.
I think that for any automaton we have a 2-category. The 0-cells are states, the 1-cells are the types associated with paths from one state to another, and the 2-cells are functions between types that respect the constraint. I haven't worked out the details however. The 2-category structure is probably important. As things stand, I've just shown how to make the types. But we don't yet have an easy way to write functions that respect these constraints. I suspect 2-categories give a language to talk about these things. But that's just speculation right now.
By the way, I couldn't write a working Show instance for Fix. Can you write one? And an implementation of arbitrary for QuickCheck?
And I hope you can now solve my problem from last week.
Leftover bits of code
K22 and K33 are constructors for 2×2 and 3×3 matrices. It would probably have been better to have used lists like Brent did.
Here's a picture of an element of a binary tree type:

The leaves correspond to elements and the letters indicate the type of those elements. If we read the leaves from left to right they match the regular expression A*B*. We can define a binary type whose leaves always match this string by making use of dissections. Similarly we can construct all kinds of other structures, such as lists and more general trees, whose leaves match this expression.
But can we make structures that match other regular expressions? Here are some examples:
1. Structures that match the expression An for some fixed n. These are structures, like trees, that have a fixed size. For the case n=5 we need a type that includes elements like:

2. Structures that match (AA)*. These are structures like trees with an even number of elements. This is easy for lists. We can just use a list of pairs. But it's more complex for trees because subtrees may have odd or even size even though the overall structure is even in size. We could also generalise to ((AA)n)* for some fixed n.
3. Structures that match A*1A*. Here's an example:

The element marked 1 is of unit type (). It's a 'hole'. So this regular expression is a derivative type. We can also construct a variety of types like those matching A*BA*CB* by using a mixture of dissection and differentiation:

4. A bytestring- or rope-like type used to represent a string that is statically guaranteed to match a given regular expression.
5. Many kinds of other constraints you could imagine on a datastructure. Like trees which are guaranteed not to have two neighbouring leaves of the same type, or whose sequence of leaves never contain a certain subsequence.
So the challenge is this: can we implement a uniform way of building any container type to match any regular expression we want?
We'll need some extensions:
> {-# OPTIONS_GHC -fwarn-incomplete-patterns #-}
> {-# LANGUAGE TypeFamilies, EmptyDataDecls, UndecidableInstances, TypeOperators #-}
First Example: Differentiating ListsLet l(x) be the type of lists of elements of type x. We can define a list type through
data List x = Nil | Cons x (List x)
Algebraically we can write this as
l(x) = 1+x l(x)Let's try approaching the derivative of a list from the perspective of regular expressions. We know from Kleene's Theorem that the set of strings (ie. the language) matching a regular expression is precisely the language accepted by a finite state automaton. Let's consider the case x*1x*. This is the language we get by considering all paths from state 0 to state 1 in the following automaton:

Note that I have overloaded the numeral '1' to mean both the type with one element (when labelling an edge) and to mean the state numbered 1 (when labelling a vertex).
Define the Lij(x) to be the type of lists whose sequence of elements correspond to all possible paths from state i to state j. A list in Lij(x) is either an empty list, or constructed from a first element and a list. If we combine an element and a list, the combination has to match a possible path from i to j. There are a number of ways we could do this. The element could correspond to a transition from i to k. But if this is the case, then the remainder of the list must correspond to a path from k to j. So we must replace Cons with something that for its first argument takes a type corresponding to a single automaton step from i to k. For its second argument it must take an element of Lkj(x). The set of paths from i to j that correspond to a single step is the (i,j)-th element of the transition matrix for the automaton. This is Xij(x) where
X(x) = (Xij(x)) = (x 1) (0 x)
On the other hand, we also need to replace Nil with a version that respects transitions too. As Nil takes no arguments, it must correspond to paths of length zero in the automaton. The only such paths are zero length paths from a state to itself. So the matrix for such paths is:
I = (1 0) (0 1)
Let's also define the matrix L(x)= (Lij(x)).
The words above boil down to:
Lij(x) = Iij+Σk Xik(x)Lkj(x)where the sum is over all the places we might visit on the first step of the journey from i to j.
We can rewrite this using standard matrix notation:
L(x) = I + X(x)L(x)Compare with the definition of ordinary lists given above. We get the type of constrained lists by taking the original definition of a list and replacing everything with matrices. We replace 1 with I. We replace x with the transition matrix of the automaton. And we replace the structure we're trying to define with a family of types - one for each pair of start and end states for the automaton. We can describe this replacement more formally: it's a homomorphism from the set of types to the set of matrices of types. (Actually, it's a bit more subtle than that. This isn't quite the usual semiring of types. For one thing, the order of multiplication matters.) And it doesn't just apply to lists. We can apply this rule to any container type. For example, suppose we wish to repeat the above for trees. Then we know that for ordinary binary trees, t(x), we have
t(x) = x+t(x)2We replace this with
T(x) = X(x)+T(x)2
We started this section by considering the specific case of the pattern x*1x* with a corresponding matrix X(x). Because X10=0 and X00=X11 it's not hard to see that any type T we constrain using this regular expression will also have similar 'shape', ie. T10=0 and T00=T11. So we can write
T = (t(x) t'(x)) (0 t(x))
where by definition, t(x)=T00(x) and t'(x)=T01(x). Suppose we have two such collections of types, (Sij) and (Tij). Now consider the types of pairs where the first element is of type Sij and the second of Tjk. Then the leaves of the pair structure correspond to a path from i to k. So we have
(st(x) (st)'(x)) = (s(x) s'(x)) (t(x) t'(x)) (0 st(x)) (0 s(x)) (0 t(x))
Multiply out and we find that
(st)'(x) = s(x)t'(x)+s'(x)t(x)In other words, the usual Leibniz rule for differentiation is nothing more than a statement about transitions for the automaton I drew above. To get a transition 0→1 you either go 0→0→1 or 0→1→1.
Although I talked specifically about differentiation, much of what I said above applies for any finite state automaton whose edges are labelled by types. The best thing now is probably to put together some code to see how this all looks.
A Specification
If you haven't checked Brent Yorgey's solution to my problem last week, now is a good opportunity. My code is a generalisation of that but it may be helpful to look at Brent's specialisation first.
The goal is to be able to define a transition matrix like this. ('K' is an abbreviation for 'constant' matrix.)
> type D a = K22 (a, ()) > (Void, a )And then define a functor like this:
> type ListF = I :+: (X :*: Y)Think of ListF being a bifunctor taking arguments X and Y.
We'd like then to able to form the matrix of fixed points of Y = ListF X Y. In this case, ordinary lists should appear as the element at position (0,0) in the matrix:
> type List x = Fix (I0, I0) (D x) ListFI'm using In to represent the integer n at the type level.
Derivatives of lists should appear at (0,1) so we want
> type List' x = Fix (I0, I1) (D x) ListFBut Fix is intended to be completely generic. So it needs to be defined in a way that also works for trees:
> type TreeF = X :+: (Y :*: Y) > type Tree = Fix (I0, I0) (D Int) TreeF > type Tree' = Fix (I0, I1) (D Int) TreeFAnd of course it needs to work with other transition matrices. For example x*1y*1z* has the following transition diagram and matrix:
> type E x y z = K33 (x, (), Void) > (Void, y, () ) > (Void, Void, z )So we'd expect
> type DDTree x y z = Fix (I0, I1) (E x y z) TreeFto define the second divided difference of trees.
The Implementation
We'll need a type with no elements:
> data VoidAnd some type level integers:
> data Zero > data S a > type I0 = Zero > type I1 = S I0 > type I2 = S I1 > type I3 = S I2Now we'll need some type-level matrices. For any square matrix, we need a type-level function to give its dimension and another to access its (i, j)-th element:
> type family Dim x :: * > type family (:!) x ij :: *(Thanks to Brent's tutorial that code is much better than how it used to look.)
We can now define matrix addition through pointwise addition of the elements:
> data (:+) m n > type instance Dim (m :+ n) = Dim m > type instance (m :+ n) :! ij = Either (m :! ij) (n :! ij)And similarly we can define multiplication. I'm using the type-level function Product' to perform the loop required in the definition of matrix multiplication:
> data (:*) m n > type instance Dim (m :* n) = Dim m > type instance (m :* n) :! ij = Product' I0 (Dim m) m n :! ij > data Product' i k m n > type instance Product' p I1 m n :! (i, j) = (m :! (i, p), n :! (p, j)) > type instance Product' p (S (S c)) m n :! (i, j) = Either > (m :! (i, p), n :! (p, j)) > (Product' (S p) (S c) m n :! (i, j)) >(Weird seeing all that familiar matrix multiplication code at the type level.)
Now we need some types to represent our functors:
> data I > data X > data Y > data K n > data (f :+: g) > data (f :*: g) > data F m f(I think phantom empty data types should be called ethereal types.)
To turn these into usable types we need to implement the homomorphism I described above. So here are the rules laid out formally:
> type Id = K22 ((), Void) > (Void, ()) > type family Hom self m f :: * > type instance Hom self m I = Id > type instance Hom self m X = m > type instance Hom self m Y = self > type instance Hom self m (K n) = n > type instance Hom self m (f :+: g) = Hom self m f :+ Hom self m g > type instance Hom self m (f :*: g) = Hom self m f :* Hom self m g > type instance Dim (F m f) = Dim m > data Fix ij m f = Fix (Hom (F m f) m f :! ij) > type instance (:!) (F m f) ij = Fix ij m fThat's more or less it. We can now go ahead and try to construct some elements. We could (as Brent suggests) write some smart constructors to make our life easier. But for now I'm writing everything explicitly so you can see what's going on:
> x0 = Fix (Left ()) :: List Int > x1 = Fix (Right (Left (1, Fix (Left ())))) :: List Intx0 is the empty list. x1 is the list [1]. The Left and Right get a bit tedious to write. But this is intended as a proof that the concept works rather than a user-friendly API.
We can explicitly implement the isomorphism with the more familiar list type:
> iso1 :: [x] -> List x > iso1 [] = Fix (Left ()) > iso1 (a:as) = Fix (Right (Left (a, iso1 as))) > iso1' :: List x -> [x] > iso1' (Fix (Left ())) = [] > iso1' (Fix (Right (Left (a, as)))) = a : iso1' as > iso1' (Fix (Right (Right a))) = error "Can't be called as a is void"So that's it! If we can write our container as the fixed point of a polynmomial functor, and if we can convert our regular expression to a finite state automaton, then Fix completely automatically builds the constrained container type.
What have we learnt?
We haven't just solved the original problem. We've shown that derivatives and dissections are special cases of a more general operation. Take a look at the definition of D x again. we can think of it as xI+Delta where Delta is the matrix
> type Delta = K22 (Void, () ) > (Void, Void)This matrix has the property that its square is zero. It's the 'infinitesimal type' I described here. In other words, this is type-level automatic differentiation. We've also been doing type-level automatic divided differencing.
We can now go back and look at the matrix form of divided differences on wikipedia. I hope you can now see that the matrix Tid(x0,...,xn-1) defined there is nothing other than a transition matrix for this automaton:

In fact, we can use what we've learnt about regular expressions here to solve some numerical problems. But I won't write about that until the next article.
By the way, I think what I've described here can be viewed as an application of what Backhouse talks about in these slides.
I think that for any automaton we have a 2-category. The 0-cells are states, the 1-cells are the types associated with paths from one state to another, and the 2-cells are functions between types that respect the constraint. I haven't worked out the details however. The 2-category structure is probably important. As things stand, I've just shown how to make the types. But we don't yet have an easy way to write functions that respect these constraints. I suspect 2-categories give a language to talk about these things. But that's just speculation right now.
By the way, I couldn't write a working Show instance for Fix. Can you write one? And an implementation of arbitrary for QuickCheck?
And I hope you can now solve my problem from last week.
Leftover bits of code
K22 and K33 are constructors for 2×2 and 3×3 matrices. It would probably have been better to have used lists like Brent did.
> data K22 row0 row1 > type instance Dim (K22 row0 row1) = I2 > > type instance (:!) (K22 (m00, m01) row1) (I0, I0) = m00 > type instance (:!) (K22 (m00, m01) row1) (I0, I1) = m01 > type instance (:!) (K22 row0 (m10, m11)) (I1, I0) = m10 > type instance (:!) (K22 row0 (m10, m11)) (I1, I1) = m11 > > data K33 row0 row1 row2 > type instance Dim (K33 row0 row1 row2) = I3 > > type instance (:!) (K33 (m00, m01, m02) row1 row2) (I0, I0) = m00 > type instance (:!) (K33 (m00, m01, m02) row1 row2) (I0, I1) = m01 > type instance (:!) (K33 (m00, m01, m02) row1 row2) (I0, I2) = m02 > type instance (:!) (K33 row0 (m10, m11, m12) row2) (I1, I0) = m10 > type instance (:!) (K33 row0 (m10, m11, m12) row2) (I1, I1) = m11 > type instance (:!) (K33 row0 (m10, m11, m12) row2) (I1, I2) = m12 > type instance (:!) (K33 row0 row1 (m20, m21, m22)) (I2, I0) = m20 > type instance (:!) (K33 row0 row1 (m20, m21, m22)) (I2, I1) = m21 > type instance (:!) (K33 row0 row1 (m20, m21, m22)) (I2, I2) = m22Update: I neglected to mention that there is a bit of subtlety with the issue of being able to create the same string by different walks through the automaton. I'll leave that as an exercise :-)
posted by sigfpe at Saturday, August 14, 2010
16 comments
![]()
![]()
